Constant Dullaart: “Ons geloof in cijfers is groter dan we denken”
Door Constant Dullaart
Als kunstenaar ben ik veel bezig met de ethische maar ook artistieke implicaties van nieuwe communicatiemedia.Ons leven is ongelofelijk veel makkelijker geworden door internet en de smartphone. De strijd tussen de grote technologiebedrijven om nieuwe, handige functies aan ons leven toe te voegen woekert voort. Als ik aan mijn vader, die in 1994 overleden is, zou kunnen uitleggen wat ik allemaal met het apparaatje in mijn broekzak kan bewerkstelligen, zou hij me niet geloven.
Maar aan al die handige tijdbesparende of sociale functies kleven ook nadelen. Zo heeft het nieuws bol gestaan van privacyschandalen rond Facebook en het beïnvloeden van democratische verkiezingen, terwijl we nog bezig waren de implicaties van de door Edward Snowden vrijgegeven informatie te begrijpen. In tijden waarin er meer naar een scherm wordt gekeken dan uit het raam, laat staan naar een schilderij, denk ik persoonlijk dat dit nieuwe medialandschap het meest interessante landschap is voor een kunstenaar. En het mooie van dit nieuwe landschap is dat het ook nog eens nieuwe materialen biedt om kunstwerken mee te maken. Niet alleen websites, interactieve installaties of sensoren die lichtjes laten knipperen, maar zelfs je publiek kun je tegenwoordig kopen en vormgeven.
Zo ben ik in 2014 begonnen met een onderzoek naar het kopen van Instagramvolgers. Instagram is natuurlijk hét platform om foto’s te delen, waar de hoeveelheid likes van je foto erg belangrijk is. Zo belangrijk dat je likes kunt kopen, nep-likes dus, en zelfs nepvolgers. Allereerst kocht ik wat volgers en likes voor mezelf. Het ergste was, dat ik werkelijk dacht dat ik een beter persoon was geworden, omdat ik als je alleen naar mijn Instagramprofiel keek - populairder leek. De kwantificatie van mijn sociale kapitaal, dus hoeveel mensen geïnteresseerd zijn in wat je te zeggen of te tonen hebt, is zeer prominent te zien op een social-mediaprofiel. Het leek daarom alsof meer mensen mijn informatie belangrijk vonden. Alsof het relevanter was wat ik te zeggen had. Het toppunt van kapitalisme: niet alleen kun je nieuwe schoenen kopen, maar ook een grote vriendenkring.
Toen begreep ik dat veel van deze social-mediabedrijven inspelen op onze menselijke angst irrelevant gevonden te worden. Alleen te zijn. Om jaloers te worden op anderen met meer sociaal kapitaal, sociale competitie dus. Maar erger nog, de kwantificatie van het sociale kapitaal wordt vaak gebruikt om aan te tonen hoe relevant kunstenaars zijn, net als kunstinstellingen, musea of zelfs politieke partijen en bewindvoerders. Hoeveel bezoekers, likes, follows, interactie zijn er? Is het wel subsidiewaardig? Heeft een kunstinitiatief het sociale kapitaal om naast de subsidie ook een crowdfundingcampagne succesvol af te ronden? Zijn er genoeg likes en follows, genoeg meetbare relevantie? Deze commerciële marktmaatstaven zijn natuurlijk niet altijd gelijk aan de andere criteria waarmee je over de kwaliteit van kunst en cultuur, of het belang ervan kunt spreken. Daarnaast zijn deze data zeer fraudegevoelig. Als u zich de museumjaarkaartfraude uit het jaar 2000 kunt herinneren, waar ‘kinderlijk eenvoudig’ museumjaarkaarten door medewerkers van instellingen door de kaartlezer werden gehaald, kunt u zich ook wel voorstellen hoe gemakkelijk online bezoekersaantallen te fingeren zijn.
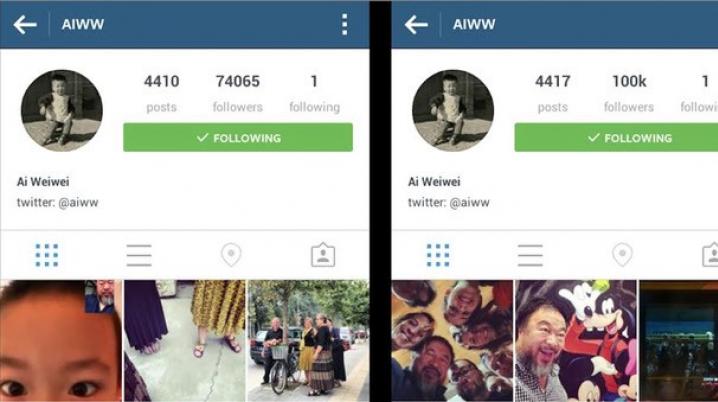
Zo wilde ik de verwarring tussen kwaliteit in de kunstwereld en de kwantificatie van sociaal kapitaal onderzoeken door een performance te doen op Instagram zelf. Voor Jeu de Paume, het fotografiemuseum in Parijs, heb ik 2,5 miljoen Instagramvolgers gekocht. Deze heb ik verdeeld over dertig accounts in de kunstwereld die zich erg bezighielden met het verkrijgen van publieksvalidatie op sociale media. Zo heb ik onder andere Ai Weiwei, Simon de Pury, Jef Koons, Hans-Ulrich Obrist en vele anderen enkele tienduizenden nepvolgers gegeven. Het doel van deze actie was dat al deze accounts gelijkwaardig aan elkaar zouden zijn. Ze hadden aan het eind elk 100.000 volgers (100k) en waren op Instagram korte tijd gelijk aan elkaar, niet meer in sociale competitie. Na deze online performance werd ik, omdat ik in het begeleidende essay genoemd had dat ik social media socialistisch wilde maken, ook wel de Lenin van Instagram genoemd.
Kort hierna werd ik gebeld door een freelance journalist van de New York Times. Zij bleek alleen geïnteresseerd of ik ook werken had verkocht via Instagram en of mijn verkoopcijfers waren gegroeid door het gebruik ervan. Nadat ik had uitgelegd wat de bedoeling was van mijn werk, stuurde ik haar de documentatie van alle accounts waar ik nepvolgers voor had gekocht, zodat de manipulatie duidelijk werd. Het uiteindelijke artikel bleek alleen geschreven te zijn ter promotie van Instagram met een opsomming van commerciële succesverhalen in de kunstwereld. Helaas werden ook de Instagramaccounts van onder meer Ai Weiwei en Simon de Pury besproken, inclusief het aantal volgers, om te laten zien hoe belangrijk zij op Instagram zijn. Aantallen die ik dus had gemanipuleerd door tienduizenden volgers te kopen.
Kortom, ons geloof en vertrouwen in cijfers is groter dan we denken - zelfs voor een krant als de New York Times - ook al weten we dat ze vals zijn. Het interpreteren van data blijft een lastige zaak, zo bleek ook al eerder uit een aantal faux pas van grote techbedrijven. Het automatisch verzamelen en interpreteren van grote hoeveelheden data, ook wel big data genoemd, is inmiddels het speelveld van een zich rap ontwikkelend veld in de informatica. Het zogenaamde machine learning, waarin een computer leert van de patronen in de data.
Maar dit kan voor grote problemen zorgen, waarbij verkeerde conclusies kunnen worden getrokken. De blink detection of oogknipperdetectie op Nikon camera’s, een functie waarbij de camera automatisch detecteert wanneer je je ogen dicht hebt, werkte in 2009 al niet goed omdat het voornamelijk op foto’s van witte Kaukasische mensen was gebaseerd. Mensen met een Aziatisch uiterlijk werden vervolgens gecategoriseerd alsof ze op elke foto de ogen dicht hadden. Maar ook Google trainde haar machine learning algoritmes op populaire foto’s, die alleen witte mensen bleken te herkennen als de categorie ‘mensen’, en mensen met een donkerdere huidskleur alleen herkende als een andere categorie, die van een dier met een menselijk gezicht, namelijk de gorilla…
Dit is slechts een kleine selectie van faux pas die het grote nieuws gehaald hebben, maar ze vormen een enorm probleem voor bedrijven die een bepaalde illusie van objectiviteit willen projecteren. Google lijkt het probleem te hebben opgelost door geen gorilla’s of chimpansees meer te categoriseren in de image search. Een noodoplossing die al jaren in stand wordt gehouden. In de discussies over de vooroordelen of voorkeuren van deze datasets, in het Engels ook wel de data bias genoemd, wordt regelmatig aangekaart dat oude culturele patronen die zich al in de data bevinden moeilijk te bestrijden zijn. Deze biases kunnen namelijk gebaseerd zijn op wie de foto’s heeft gemaakt. Was dat een man of een vrouw, jong of oud, wat voor besef van rijkdom of cultuur had deze persoon, of van diversiteit? Wie heeft de informatie gecategoriseerd, gelabeld, toegankelijk gemaakt? Is een beeld gekenmerkt als mooi, fijn, rustig of lelijk? Binnen de technologie wordt vaak de oplossing gekozen om de computers wat harder te laten werken, of beter te instrueren met regels om te voorkomen dat ongewenste uitkomsten naar voren komen.
Maar het blijft natuurlijk altijd de vraag hoe de data aangeleverd zijn. Zo zou de nieuwe website en database van DutchCulture bijvoorbeeld kunnen dienen om voorkeuren binnen het Nederlandse beleid aan de kaak te stellen. Hebben vrouwelijke kunstenaars na het krijgen van een kind nog wel gelijke kansen op tentoonstellingen in het buitenland? Of worden de diversiteit doelstellingen van de Nederlandse fondsen wel gehaald, en hoe zou dit beter kunnen? Dit zou overigens wel betekenen dat de informatie die nodig is om dit soort conclusies te kunnen trekken ook de database in zou moeten. En wanneer zaken als ras, sekse en andere gevoelige informatie verzameld worden, is de integriteit voor het bewaren ervan en de bijbehorende privacy erg belangrijk.
De vraag is natuurlijk of we dit moeten willen. Zelf heb ik op bedevaart naar de hoofdkantoren van Google in interessante gesprekken gevoerd met programmeurs die zich terdege bewust zijn van de verantwoordelijkheid die op hun schouders rust. Deze verantwoordelijkheid is des te groter als je weet dat je eigenlijk geen dataset zonder voorkeuren kan creëren of interpreteren. Het is voor veel mensen bij Google wel duidelijk dat ze geen objectieve visie op alle informatie die door de mensheid gegenereerd wordt, kunnen geven. Er bestaat nu eenmaal geen humanistische overkoepelende wereldvisie die elk mens evenredig vertegenwoordigt. Er ligt altijd wel een vooroordeel, een bias, in verscholen. Eigenlijk bestaat cultuur uit niets anders dan een set voorkeuren.
Het mooiste zou zijn als je door een lens van deze voorkeuren zou kunnen kijken zodat je je beter kan informeren dan wel inleven. Hoe ziet een puber in Bangladesh de wereld in vergelijking met een blokkeerfries bijvoorbeeld? Deze vergelijking lijkt tot nu toe vergezocht, mede omdat er meer geld te verdienen valt met het tonen van informatie aan een blokkeerfries waar deze op wil klikken, dan met informatie waar de wereld beter van zou kunnen worden.
Tot de tijd komt dat we makkelijk van data bias naar data bias kunnen schakelen, moeten we controleren hoe data gegenereerd worden en de archieven in gaan. Zo ook de archieven van DutchCulture. Hoe bewaren we de integriteit van de informatie die te raadplegen is, hoe weten we zeker dat deze zo representatief mogelijk is? Maar ook, hoe verzinnen we manieren om anders naar deze data te kijken? Om een database te gebruiken om vooroordelen tegen te gaan, moet het vooroordeel ook duidelijk worden in de data, namelijk in vergelijking met andere data zonder dat vooroordeel. Hierdoor is het van het grootste belang om de integriteit in het verzamelen van de data permanent, constant ter discussie te stellen en te controleren. Zodat niet de reeds bevoorrechte posities zichzelf alleen maar verstevigen, maar wij nieuwe technologische mogelijkheden daadwerkelijk kunnen ontsluiten voor iedereen.
Deze tekst is een geredigeerde versie van een eerder voorgedragen keynote ter gelegenheid van de presentatie van de nieuwe DutchCulture website en database te Amsterdam in december 2018.
